It's time we start securing our CICD pipelines
TL;DR Automations through CICD pipelines have expedited security scanning and delivery of application to cloud. At the same time such automation functions are being made available ready-to-use in the open marketplaces like tekton catalog or Github Marketplace. Therefore, we need to start thinking about securing the supply-chain for CICD pipelines itself.
Before diving into the CICD pipeline security discussion, I want to talk about the way open-source ecosystem is influencing different aspects of software lifecycle management, from development, packaging, security scanning and much more. Open source ecosystem is growing at an unprecedented pace. At the same time, it is evolving in different granularities and dimensions. At the platform or infrastructure level we started with linux to now docker and kubernetes. Personally I believe the major open source expansion is happening at application level. We can roughly categorize this expansion at application level into categories shown below. (In no way, I claim this list is exhaustive, but it is presented to drive the discussion in this blog.) These categories or modes of open-source contributions could be viewed as a chronological order of evolution, but there is no evidence to suggest the later ones are replacing the older modes. In fact, I think there is a tremendous growth of contributions in each of these categories.
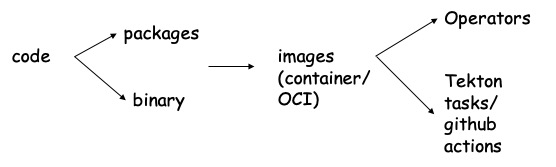
Let’s first talk about these modes at application level for a moment. At the most granular level, the open source exchange happens by sharing the raw code/functions from git repositories, stackoverflow, etc. Next, the code can be packaged, compiled together to be made available as a library or an executable binary. Libraries can be downloaded from standard package registries like pypi, npm, maven or from OS distros like debian, alpine. While binaries are typically available through release bundles or directly from some object stores (remember how you installed kubectl CLI last time).
Then a big nexus event occurred , i.e. containers. (yes, about nexus event – according to Marvel’s fantasy universe, nexus event is a significant event that causes a branch to break off from the Sacred Timeline to create new realities) Through container images, we started distributing applications with base OS and language runtimes and all required package dependencies. If you need a database, you simply run
docker run --name some-mysql -e MYSQL_ROOT_PASSWORD=don't-tell -d mysql.
But, yes you still had to be responsible for managing lifecycle (scaling/migration) of these applications. Then, with operators the onus of managing lifecycle for applications is switched from user to open-source operator providers.
Containers allowed breaking monolithic applications and business logic into modular components that can be developed independently and quickly. Such an accelerated development pattern then required a high velocity path from code to container that gave rise to innovation and automation in CICD pipelines. CICD pipelines aim to facilitate expedited testing, security scanning and delivery of applications to cloud through automation. As a result, we are witnessing a new open-source ecosystem around CICD pipelines.
More specifically, I will talk about two CICD technologies I am intimately familiar with, viz. “Tekton” and “GitHub Actions”. Both these technologies have a growing open-source marketplace where common utility functions (like git-clone, lint-scan..) as well as specialized security and compliance functions (like static-scan, vulnerability-scan..) are made available. Tekton, for instance has tektoncd/catalog where more than 50 tasks are available. While GitHub has Marketplace, where more than 800 github actions are available just for code quality checks.
While consumption of open source software allows faster development, it also puts our CICD pipelines at risk from malicious penetration in the supply chain. For example, in the pipeline shown below, individual tasks are authored by different open source vendors. The code-clone task clones given repository and initializes shared workspace for remaining security and compliance tasks. In this case, if the code-clone is compromised in performing its intended desired function, i.e. it adds/updates/removes some code artifacts after cloning the original code, then the analytic performed by remaining tasks is automatically compromised.
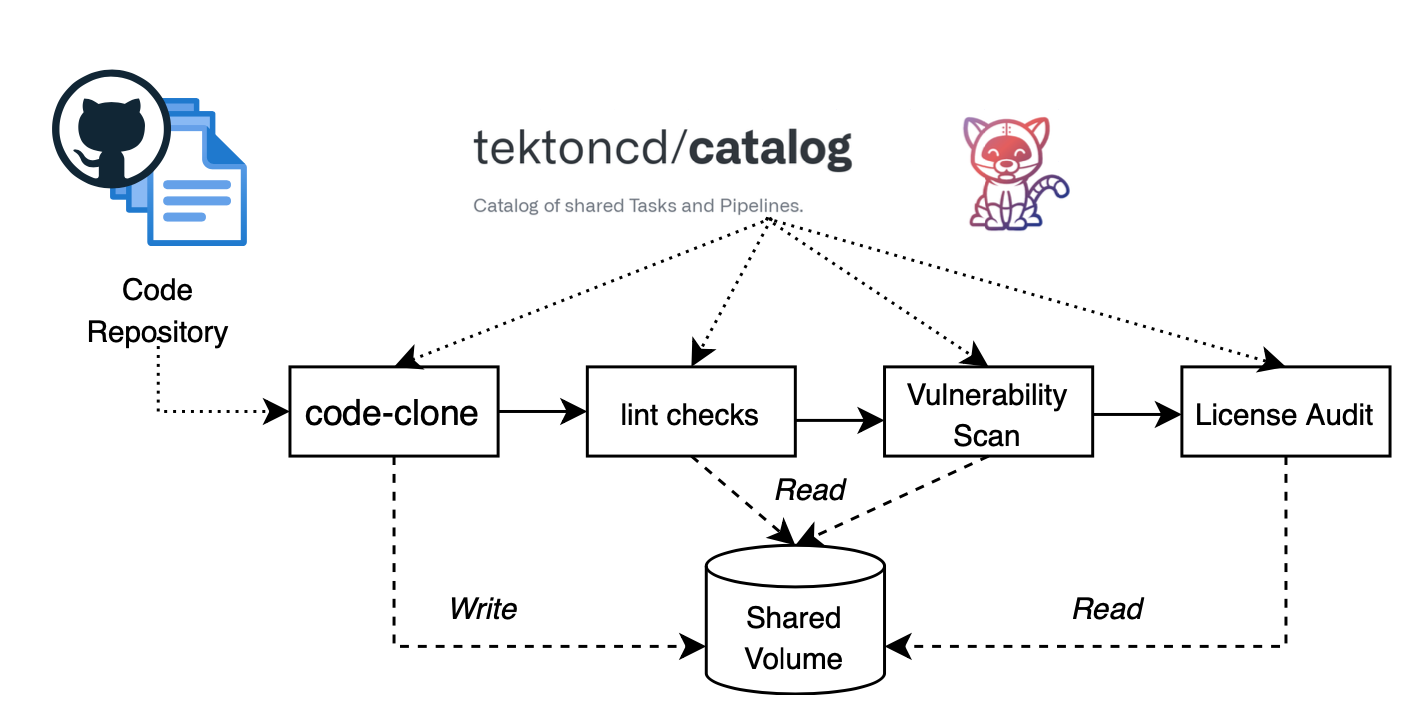
Thus, as we are building CICD DevSecOps pipelines for securing application scanning and delivery, our pipelines as-is can not be the root-of-trust. In other words, we need to make sure our CICD pipelines are “secure” at the composition to begin with. We are (somewhat) familiar to how we (think we) secure packages and container images by generating SBOM, scanning all dependencies for vulnerabilities, auditing them for licenses, and more. In the wake of recent supply chain attacks, we realized the breadth of the scanning we do is not enough, but let’s leave it for an another blog. For CICD what it means to start securing pipelines ?
For brevity, let’s call the tekton tasks or github actions as CICD functions and the compositions in which they are used like tekton pipeline or github workflow as simply pipelines. Function definitions (tekton-task.yaml or action.yaml) typically has two sections, (a) configuration and (b)execution. Configuration section contains metadata like name, input/output arguments, default values for input arguments, declaration of shared resources and like. While execution section declares a script/binary or an image and an actual command to run. Pipeline definition, on the other hand declares order in which these functions can be invoked and pass-on different configuration values to these functions. When we are talking about securing a pipeline, we can start considering following dimensions:
-
Secure Pipeline Layout: We need to secure the order of execution for functions in the pipeline. We also need to ensure correct Read/Write access to the shared resources for functions.
-
Secure the data flow in the pipeline: As functions execute inside a pipeline, they typically produce some new artifacts. For instance,
git-clonetask would produce a source code clone directory orvulnerability-scannerwould produce a JSON report about discovered vulnerabilities. These artifacts could be input to another function, like vulnerability report can be consumed byjira-msgto open an issue orslack-msgto send a message. We need to ensure the data flow within a pipeline is secure as well. -
Secure Task configurations: We need to secure integrity of task configurations, such that any changes to the default values, input/output parameters can be signed/verified to be coming from trusted sources.
-
Secure Task Execution Commands: This is one critical requirement. We need to ensure the execution base (binary/image/script) is coming from trusted source, has no vulnerabilities and
run commandhas not been tempered by un-authorized sources. -
Secure innovation of pipeline: For better usability, pipelines typically offer multiple modes for triggering an execution, for instance manual trigger (
kubectl -f apply pipelinerun.yaml/taskrun.yaml), timed trigger (cronjob scheduled) or event tigger (on pull_request or push from git). So we need a way to verify and authorize the source of the trigger before executing a pipeline. -
Admission gate for execution : It never hurts to be double sure:) While we can perform these pipeline security checks by statically scanning the pipeline definitions, it always helps to enfore them at the runtime. So when an authorized event triggers execution of the pipeline, we need to verify pipeline/task/resources/parameters before instantiating the pipeline.
Then once your pipeline starts executing, there is some great work going-on with tektoncd/chains that monitors task executions in the cluster, sign and attest execution state as well as produced artifacts.
Ok, so far we discuss a lot about Why and What about pipeline security theoretically, that leaves us to the practical aspect of How? In the next blog, we will dig deep in evaluating existing and emerging technologies to our need and try to build the right solution.
Again, for inputs or feedback please feel free to reach out to me on Twitter/Github/Email.